
{kind=link}
This article takes a deep dive into web application architecture with designing a real-world use case. If you have zero knowledge on the domain, after going through this article, you’ll have a fundamental understanding of the components involved in the web application architecture and how we build web applications fitting those components together like LEGO blocks.
So, without further ado, let’s jump right into it.
Typical web application architecture diagram
Here is a generic architectural diagram of a web application that you’ll find in most of the applications running online today.

It contains:
- The user interface component
- Backend application server
- A message queue
- Database
You’ll find these components in most of the applications running online today on the web. Now we can further add more components to this architecture, such as the load balancer, CDN, cache, etc.

Every component in the architecture has a specific role. We will get into that, but let’s begin with the fundamental components of the application architecture.
User Interface
The user interface component gets displayed right into our browsers in the form of web pages. Web pages are written using HTML, JavaScript, CSS, and a plethora of JavaScript frameworks such as Angular, React, Vue, Svelte, etc., including a big number of JavaScript libraries.
The interaction between the client (user interface) and the backend server involves a lot of technologies, such as AJAX, AJAX Long polling, HTML5 Event Source, Server-sent Events, Web Sockets, Streaming over HTTP, and more.
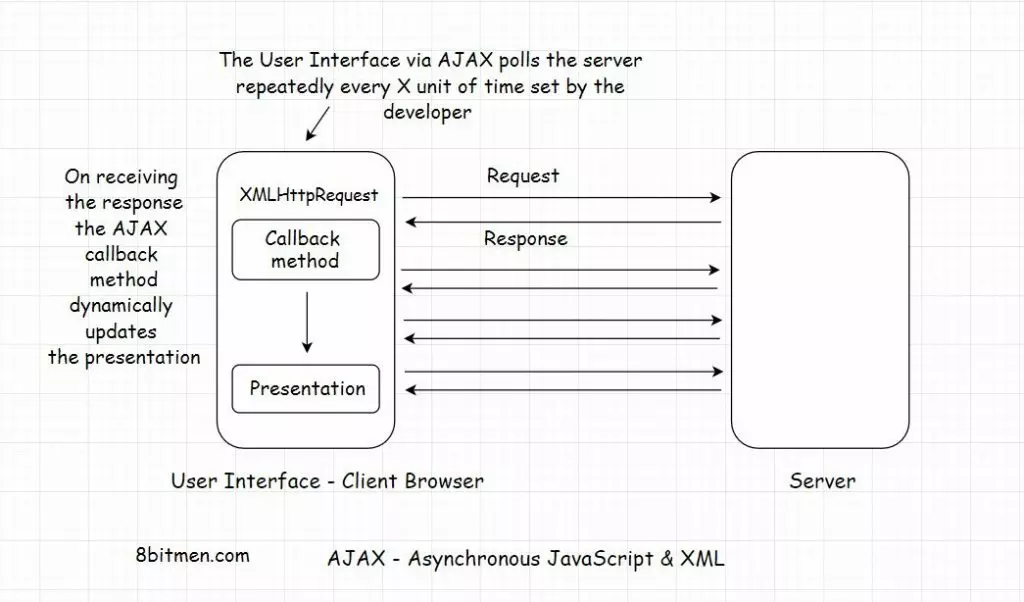
Every technology stated above has a specific use case; for instance, Web Sockets are preferred when we need a persistent bi-directional low latency data flow from the client to the server and back.
Typical use cases of web sockets are messaging, chat applications, real-time social streams, browser-based massive multiplayer games, etc. These are apps with quite a significant number of read-writes compared to a regular CRUD-based web app.
Discussing every client-side technology would be overwhelming for an introductory write-up on web architecture. So, I am gonna skip them for now.
Though, if you want to understand web application architecture in-depth, check out my Web Application and Software Architecture 101 course.
In this course, I take a deep dive into the modern application architecture, going into the details of every component, including the discussion on concepts like different tiers in the application architecture, the need for them, scalability, high availability, monolith and microservices, micro-frontends, message queues, stream processing, databases, mobile apps and more with relevant real-world examples.
Client-side and Server-side Rendering of the User Interface
When a browser receives a web page from the server in response, it has to render the response on the window in the form of an HTML page.
To pull this off, the browser has several components, such as:
- The browser engine
- Rendering engine
- JavaScript interpreter
- Networking and the UI backend
- Data storage etc.
I won’t go into much detail; the gist is the browser has to do a lot of work to convert the response from the server into an HTML page. The rendering engine constructs the DOM tree and renders and paints the construction, and so on.
This process is known as client-side rendering.
Naturally, all this activity takes some time before the user can interact with the page.
To cut down all this rendering time on the client, developers often render the UI on the server, generate HTML there and directly send the HTML page to the UI. This technique is known as server-side rendering.
It ensures faster rendering of the UI, averting the UI loading time in the browser window because the page is already created, and the browser doesn’t have to do much assembling and rendering work.
The server-side rendering approach is perfect for delivering static content, such as WordPress blogs. It’s also good for SEO because the crawlers can easily read the generated content. For modern dynamic AJAX-based websites, where sections of a web page get updated in real-time, the client-side rendering works best.
We generally leverage a hybrid approach to get the best of both worlds. We can use server-side rendering for the static content of our website and client-side rendering for dynamic.
Moving on to the backend server.
Backend Application Server
The backend application code is written in backend programming languages like Java, Python, PHP, etc. It mostly holds most of the business logic of the service.
Why do I say mostly?
Because in some cases, it’s advantageous to put the business logic on the UI (User Interface). Though, this needs a consideration of the trade-offs involved.
Keeping the business logic on the UI keeps the latency of the application low, proving to be an upside. Since the business logic and the user interface reside in the same machine, there are fewer network calls to the backend server, but the code is vulnerable to being accessed by evil people. Anyone can peep at the business logic of our application.
Taking a to-do list app as an example, if the business logic is on the UI, the application makes a call to the backend server only when the user has finished creating their list and wants to persist the data. There is no need to send a request to the backend server every time the user adds/deletes or modifies an item to their list.
Another example is a browser or a mobile app-based game. The game files are pretty heavy, and they only get downloaded on the client once when the user uses the application for the first time. And they make the network calls to the backend only to persist the game state. All the logic resides on the UI.
Additionally, fewer server calls mean less money spent to keep the servers running, which is naturally economical.
I’ve discussed the concept in much more detail in the “Different tiers in the web application architecture” chapter in my course.
Application Flow
The user interface is called the client in the architecture and the backend component is the server. Ideally, any application component or an entity that sends a request to the server is termed as a client.
So, here is the application flow:
The user interacts with the user interface. The UI sends a request to the backend server to run the business logic in accordance with the user’s activity.
The backend server sends a request to the database to persist the user state and the data. The requests typically sent by the UI are CRUD (Create, Read, Update, Delete) of data.
Moving on to the database component.
Database
The database is the component that persists the data in the application. Speaking of data, there are different forms of data such as structured, semi-structured, unstructured and the user state.
There are different databases to handle different data forms, such as data involving a lot of relationships and connections between each other, typically seen between users and entities in a social network, fits best to be stored in a graph or a relational database.
For ACID transactions and strong consistency, picking a relational database is a no-brainer.
When we need fast read writes, we can look towards NoSQL databases like MongoDB (a document-oriented database) or Cassandra (a column-family database). NoSQL databases are built with scalability in mind. They are designed to auto-scale on clusters without much fuss and human intervention.
Looking to store streaming data with time as an important data point, like stock price movement, look for a time-series database.
When discussing databases, there are a lot of concepts and trade-offs involved and I am just oversimplifying things here.
I’ve discussed all these concepts in my course and will soon be adding a new chapter on scaling databases to it.
Message Queue
A message queue, as the name says, is a queue that routes messages from the source to the destination or the sender to the receiver following the FIFO (First in, first out) policy.
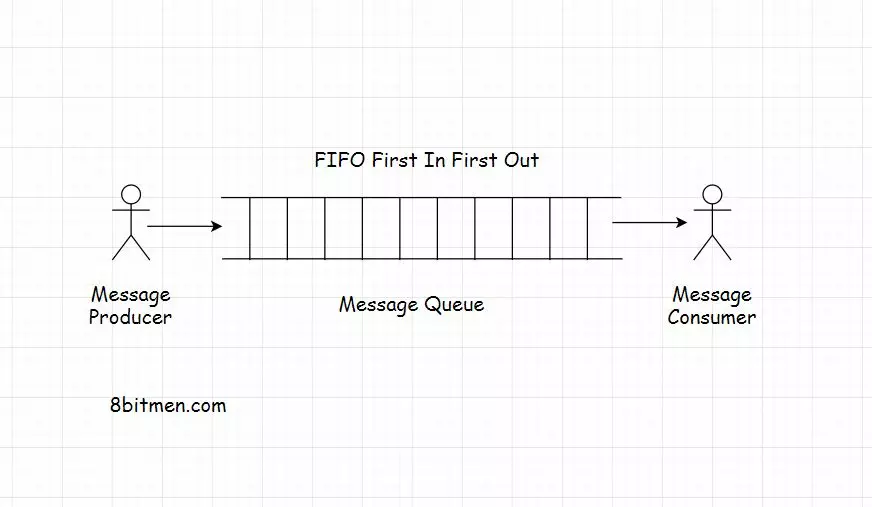
Message queues facilitate asynchronous behavior in web applications. Asynchronous behavior allows the modules to communicate in the background without hindering their primary tasks.
Message queues facilitate cross-module communication, which is key in service-oriented/ microservices architecture, enabling communication in a heterogeneous environment and providing temporary storage for storing messages until they are processed and consumed by the consumer.
Let’s understand this with the help of a real-world example.
Message Queue Real-world Examples
Take an email service as an example. Both the sender and receiver of the email don’t have to be online at the same time to communicate with each other. The sender sends an email, and the message is temporarily stored on the message server until the recipient comes online and reads the message.
Another example, think of a user signing up on an application. After they sign up, they are immediately allowed to navigate to the application’s homepage, but the sign-up process isn’t complete yet. The system has to send a confirmation email to the user’s registered email id. Then, the user has to click on the confirmation email to confirm the sign-up event.
However, the website cannot keep the user waiting until it sends the email to the user. They are immediately allowed to navigate to the application’s home page to avert them from bouncing off.
So, the task of sending a sign-up confirmation email to the user is assigned as an asynchronous background process to a message queue. It sends an email while the user continues to browse the website.
This is how message queues are leveraged to add asynchronous behavior to an application. Message queues are also used to implement notification systems similar to Facebook notifications, which I’ve discussed in the course.
Now, let’s understand a few additional components in the web architecture: Cache and the Load balancer.
Cache
Application caching ensures low latency and high throughput. An application with caching will undoubtedly do better than an application without caching simply because a cache intercepts all the requests darting towards the database and provides the response with very low latency.
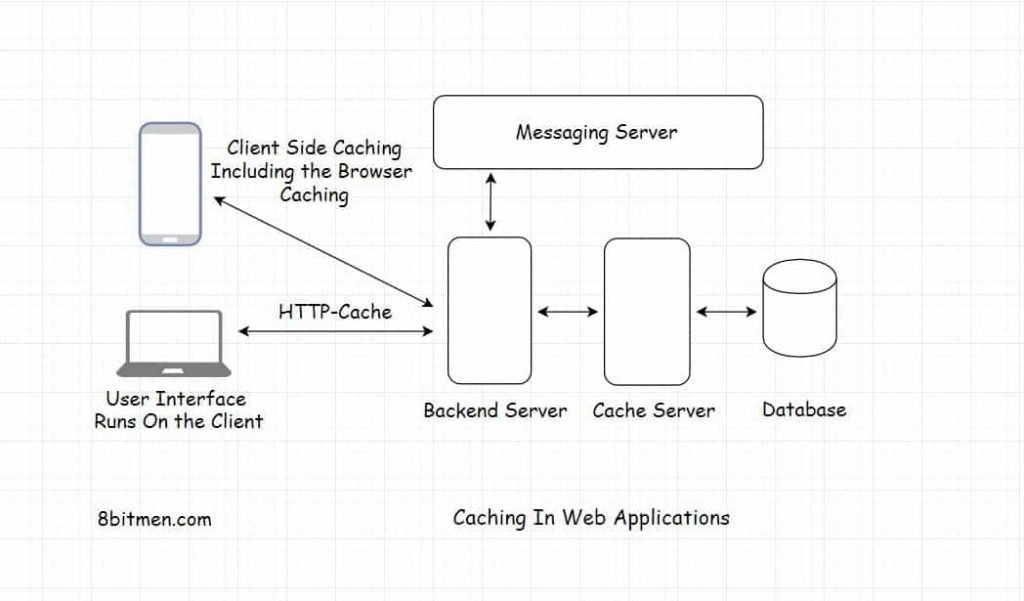
Intercepting the database requests allows the database to free its resources to work with other requests, those requesting uncached data, open connections or write operations.
Implementing caching in a web application means copying frequently accessed data from the database disk and storing it in RAM (Random access memory) for quick response.
A cache can always handle more read requests than a database since it stores the data in a key-value pair and does not have to do much computation when returning the data in contrast to a database.
Frequently requested data queried from the database with the help of several table joins can be cached to avert the same joins query from being run every time the same data is requested. This increases throughput, performance and saves resources.
Load balancer
Load balancing enables our service to scale well and stay highly available when the traffic load increases. Load balancing is facilitated by load balancers, making them a key component in the web application architecture.

Load balancers distribute heavy traffic load across the servers running in the cluster based on several different algorithms. This averts the risk of all the traffic converging to a single or a few machines in the cluster. Here is a detailed read on CDNs and load balancers on this blog.
If the entire traffic on a particular service converges only to a few machines, this will cause an overload, subsequently spiking the latency also bringing down the application’s performance. The excess traffic might also result in the server nodes going offline. Load balancing helps us avoid all these nightmares.
While processing a user request, if a server goes down, the load balancer automatically routes the future requests to other up and running server nodes in the cluster. This enables the service as a whole to stay available.
Load balancers act as a single point of contact for all client requests.
They can also be set up at the application component level to efficiently manage traffic directed towards any application component, be it the backend application server, database component, message queue, or any other. This is done to uniformly spread the request load across the machines in the cluster powering that particular application component.
At this point in the article, I am sure you have a preliminary idea of web architecture. Now, let’s design a simple sports news web service putting together all the components we have learned. It will make things more clear.

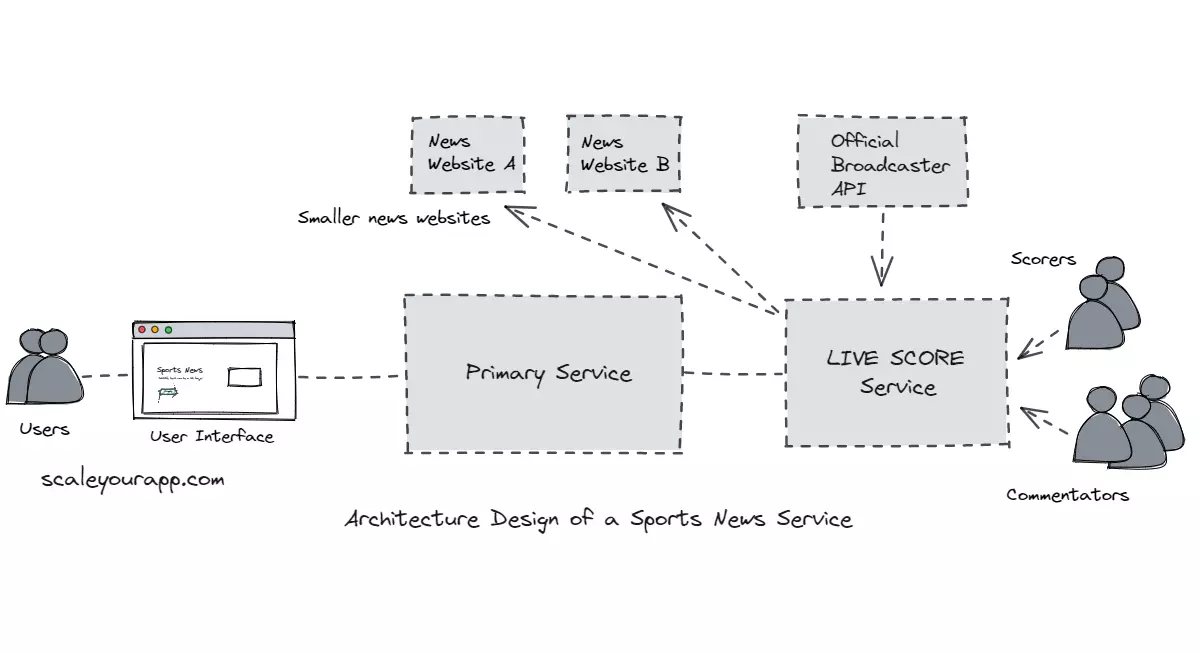
Designing the architecture of a sports news service like ESPN
Though the real-world architecture of a service like ESPN would be overly complex, I have oversimplified the architecture to avoid being overwhelmed and help you understand the concepts one step at a time.
Microservices
A service like ESPN will have a microservice architecture as opposed to being a monolith.
Why?
There will be different services having the onus of running specific functionalities of the system. For instance, there will be a service “LIVE Score Service” to persist the manually input data from the commentators and the scorers of every game. And the service will then move that data to the primary service to be displayed on the website.
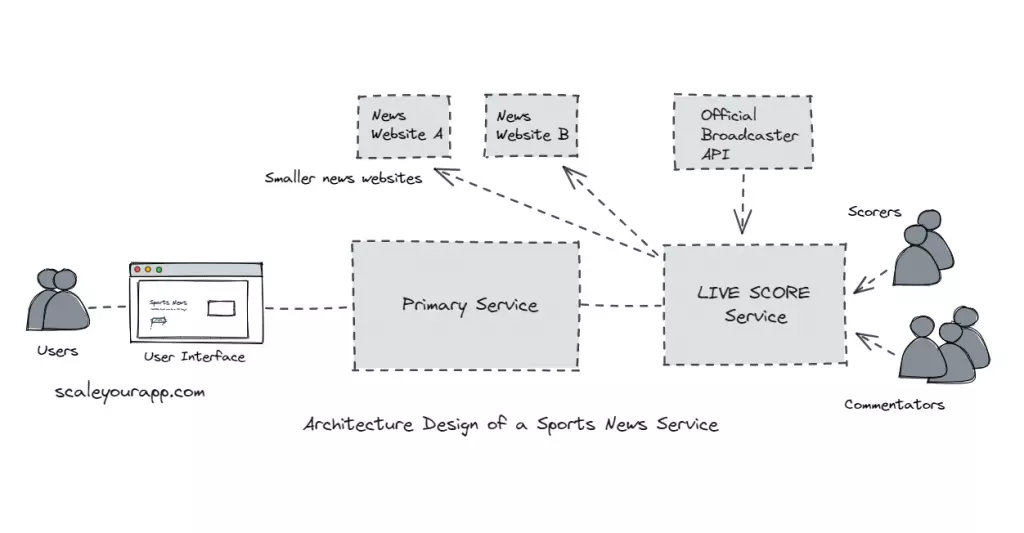
Now, a site as big as ESPN would cover several sports such as Cricket, Baseball, Basketball, Football and so on. We can have a dedicated microservice to ingest data of every sport.
Why do we need to have a separate microservice for every sport? Why not one?
A respective microservice for a particular sport will have several responsibilities, such as:
- Ingest the manually input data from the commentators and the scorers and move it to the primary service in real-time.
- Programmatically ingest data from the authorized broadcaster API of the sport if there are any. For instance, the official broadcaster may expose a dedicated score API for sports websites at a certain subscription price.
- Run business logic on the ingested data. Every sport will have separate business logic to be run on the data before it is passed to the primary service.
- Pass on the processed data (after adding their flavor) to other third-party services like news websites, gaming apps, etc., via an API at a certain subscription rate.
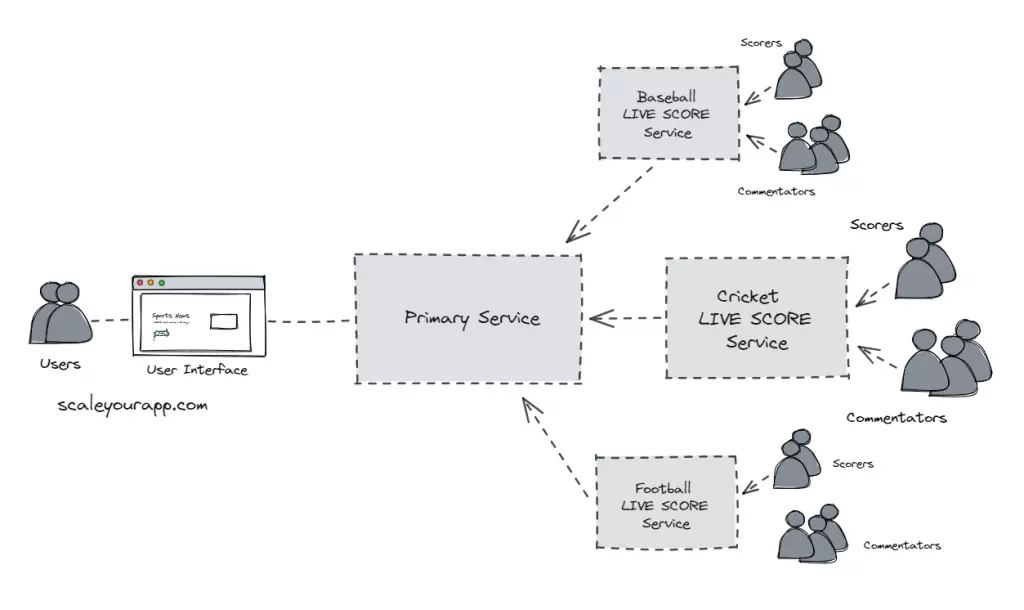
It’s a cleaner approach to have a dedicated microservice for every sport. We can always tweak the code of a particular microservice without much fuss, keeping the ESPN architecture loosely coupled and highly available.
Dedicated teams with respective domain knowledge can be assigned to work on the services of the respective sport. Also, in case there is a bug in a certain service, let’s say, the basketball service, which makes the service go down, other sports on the website stay unimpacted.
Microservices: Tech Stack
Speaking of the microservices tech stack, any mature backend language like Java, Python, etc., can be picked to write the microservice.
Every service will expose the data to the primary service via REST API and will also have a UI for the scorers and the commentators to feed their data in.
The UI has to be responsive to be able to adjust well on small mobile windows as well as the desktop browser windows. We can also develop a mobile app for feeding in the data that would push the data to this particular sport microservice but let’s just stick to the responsive UI for brevity.
Picking the right database is important here. We need fast read writes. A NoSQL database like Mongo DB or Cassandra will fit best for this use case. Cassandra is a column-family database built to handle petabyte-scale data, specializing in handling a lot of writes.
Though in this case, only a limited number of resources would be updating the scores in real-time as opposed to millions of readers performing writes. Mongo DB would suit best as a database here.
Moving on to the primary service.
Primary Service: ESPN Service for the End-User
A few primary responsibilities that the primary service will have are:
- Ingest data from respective sports APIs and display the information on different sections of the web page.
- Display customized data to the user based on their preference and subscription plans.
- Display relevant ads to the end-users.
Once the ESPN website receives data from different microservices, it has to update different sections on the site’s page with the latest information. This can be done by leveraging AJAX, SSE (Server-sent events), HTTP Streaming, etc.
Message Queues can be leveraged to build a notification system to send real-time notifications/scores to the end-users on their mobile or desktops. In my web architecture course, I’ve discussed how notification systems are developed using message queues.
Speaking of user data, based on their preferences and the subscription plans they have purchased, the website has to present the relevant data. The primary service has to run the business logic for all this on the backend before it displays data to the end users.
It also has to keep track of the ads that are to be displayed on the website. We can have a separate service for this if the ad system is too complex.
For instance, a site as big as ESPN would accept direct sponsorship ads from various companies based on the display location on the website, the viewer’s demographics, sports interests, and more. Also, manually communicating with companies is often not scalable. The site needs an ad slot purchase system that would enable the sales teams of companies to purchase the slots on the site without having to spend a lot of time communicating with ESPN back and forth.
The site would also run ads from other third-party ad providers such as Google Ads. All this functionality would demand a separate service.
Primary Service Tech Stack
Again the backend can be written with any of the mature backend languages like Java, Python, etc.
We would need a relational database like MySQL here as we need strong consistency and ACID transactions for the sponsorships and the subscription plans purchase transactions. A relational database would also fit best for storing normalized user data.
A cache like Memcache, Hazelcast, etc., can be leveraged to implement caching with short TTLs (Time to Live) since the site is read-heavy.
Service Deployment
Different sports services can be deployed on the cloud in the cloud regions nearest to the end-users. For instance, the Cricket microservice can be deployed near the Indian sub-continent considering the heavy number of viewers from this geo-location. This is just one assumption, there would be other factors involved too like the countries playing the game, game venue etc.
On the other hand, the Baseball microservice can be deployed in a cloud region in the US following the same logic. We can also leverage the cloud edge locations to cut down the application latency as much as possible.
Old data from past games can be archived by leveraging the cloud storage (Object, file or block).
If you want to understand how the cloud deploys, scales, and monitors our services globally, the complete deployment infrastructure, and the workflow, check out my platform-agnostic cloud fundamentals course.
Well, Folks! This is pretty much it on the architecture of our sports website. I can go on and on till the minutest of details, but I believe this will suffice for an introductory article on web architecture.
Where to go next?
Check out the article on application architecture which is a continuation of this, where I’ve discussed a high-level architecture of a food delivery service in detail.
If you found the content helpful, consider subscribing to my newsletter below to get the content published on this blog and more directly to your inbox. Also, do share it with your network for better reach. You can read about me here.
I’ll see you around.
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go


Follow Me On Social Media