
This is my second write-up on the infrastructure @Twitter. In the first, I delved into the database technologies leveraged by the social platform to store petabytes of data generated every single day.
Twitter recently moved a part of their workload to the Google Cloud to free their resources of the effort that went into managing the on-prem infrastructure at Twitter scale that is managing hundreds of millions of tweets, processing over a trillion events, ingestion of hundreds of petabytes of data, execution of tens of thousands of jobs over a dozen clusters every single day with scalability and high availability being a crucial factor.
Finally, Twitter took the call to migrate their services to the cloud to increase their productivity.
The engineering team at Twitter started a rigorous cloud evaluation process, meditating on various options available in the industry that could manage something at Twitter scale.
They brooded over if they had to re-architect the existing services for the cloud, if the existing tech had to be replaced with the proprietary tech offered by the cloud vendor or just lift & shift the workload from on-prem to the cloud.
They considered several cloud providers. Ran functional tests, micro & macro benchmarks and tested for scale on the cloud to validate if a certain cloud platform fit their needs.
Micro-benchmarking helped them get an insight into the resources they would have to depend on, for instance, different cloud storage classes and such. Macro benchmarks & scale testing helped them gauge the performance.
All the tests and iterations took them over a year. Finally, they picked Google Cloud, and Google’s infrastructure suited their requirements pretty well. The cloud platform provided flexibility in both storage and compute with a high-speed network.
The Migration Phase
For the migration, a plan, pipeline, timeline and financial projections were prepared with the sole motive to avoid any sort of disruption to the existing platform functionality.
To cut risks, a divide & conquer approach was chosen which meant moving small parts of the complete workload to the cloud, split things up and learn as they go.
Twitter first picked their cold storage data and Hadoop clusters to move to the Google Cloud. Simply because if anything went south, it would have a minimum immediate direct impact on the running services. Risks were comparatively lower in this case.
They eventually moved approx. 300 petabytes of data to Google cloud storage.
To read more about the persistence technologies & Hadoop cluster used at Twitter check out this article on the blog: What databases does Twitter use?
Architecture
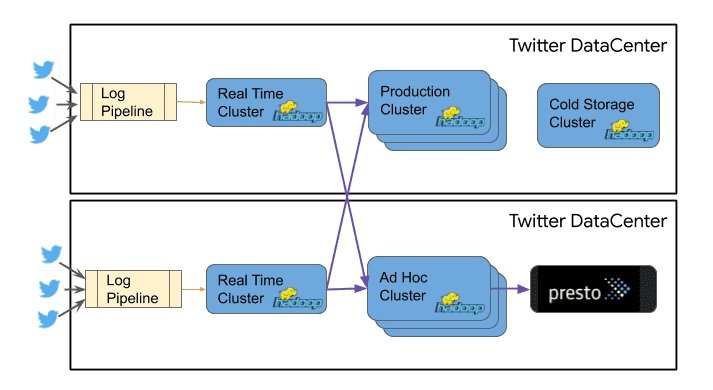
Twitter originally started using Hadoop in its infrastructure to take MySQL backups but over time the use cases for the tech grew manifold. Today Hadoop at Twitter is used to ingest real-time data generated by the end users on the platform, run back-end production jobs, helps the engineering team manage not so frequently accessed data, social graph analysis, API analytics, user engagement prediction, recommendations, ad analytics, and more.
When migrating the Hadoop clusters to the cloud, the cold storage clusters were picked while the production Hadoop clusters remained on-prem for the reason I’ve stated above minimizing risk.
The diagram below shows Hadoop clusters at Twitter’s on-prem infrastructure. The CPU in the cold storage cluster was underutilized in comparison to the CPU utilization of other clusters.
Moving Data to Google Cloud
Data is continually generated on the platform in real-time with its size augmenting with time. To transfer the data, the engineering team needed to establish a performant network connection between Twitter and Google Cloud.
They used an 800 Gbps redundant direct peering network connection between the two platforms to transfer the data. In every data center, dedicated copy clusters were setup with the sole aim to transfer data over from Twitter to Google Cloud.
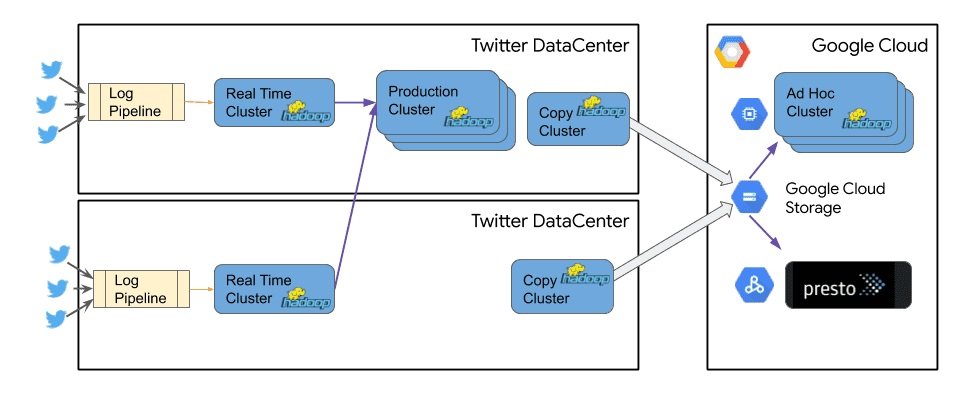
To process the data, Twitter uses Hive, and Presto queries which translate into DAG Direct Acyclic Graph jobs that run over the clusters. On the cloud the same tasks are run using products like Cloud Dataflow, Cloud Dataproc and BigQuery managed services.
Google Cloud Dataflow is a fully-managed serverless real-time streaming and batch data processing offering.
Cloud Dataproc is a fully managed cloud service for running Apache Spark & Hadoop clusters in a cost-effective way. It provides a comprehensive platform for data processing, analytics and machine learning & BigQuery is a serverless scalable data warehouse with an in-memory business intelligence engine.
As you can see in the diagram above, all the data generated by the users at Twitter still flows through the on-prem infrastructure of the platform and is then replicated over to Google Cloud.
Since in the new architecture the compute and storage for the Hadoop workload are separate it enabled Twitter to save tens of thousands of underutilized provisioned CPU cores.
For more information on Hadoop implementation on Google Cloud do go through the videos below from Google Cloud’s YouTube channel.
How @TwitterHadoop Chose Google Cloud (Cloud Next’)
Visualizing Cloud Bigtable Access Patterns at Twitter for Optimizing Analytics (Cloud Next’)
Folks, this is pretty much it. If you found the content helpful, do share it with your folks.
Mastering the Fundamentals of the Cloud
If you wish to master the fundamentals of cloud computing. Check out my platform-agnostic Cloud Computing 101 course. It is part of the Zero to Mastering Software Architecture learning track, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning track takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.

You can read about me here. I’ll see you in the next write-up.
Until then.
Cheers!!


Follow Me On Social Media