
{kind=link}
Facebook’s photo storage architecture
Facebook built Haystack, an object storage system designed for storing photos on a large scale. The platform stores over 260 billion images which amounts to over 20 petabytes of data. One billion new photos are uploaded each week which is approx—60 terabytes of data. At peak, the platform serves over one million images per second.
Let’s understand the retired Facebook’s NAS (Network-attached storage) over NFS (Network file system) based photo storage architecture and the issues that triggered the need for the new object storage system (Haystack).
Retired NAS over NFS-based photo storage architecture
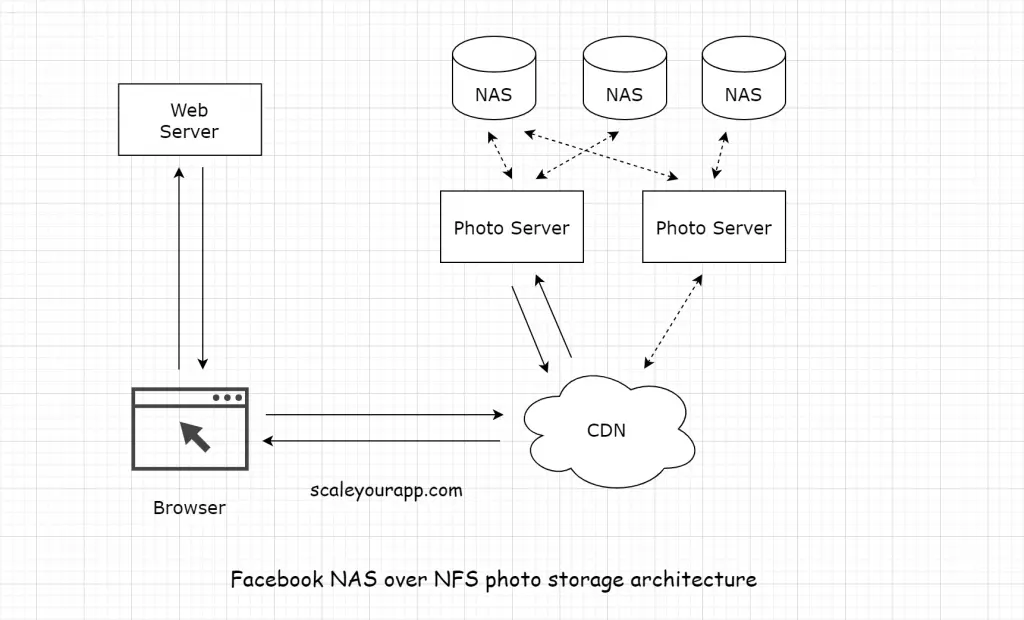
Sequence of events:
The browser sends a request to the Facebook web server for a particular photo.
The web server constructs a url for the photo and directs the browser to a CDN. If it’s a cache hit, CDN returns the photo.
If not, CDN sends the request to the photo servers. The photo servers process the request containing the url. They mount all the volumes exported by these NAS appliances over NFS. They fetch the photo from the NAS storage over NFS (Network File System).
The photo is returned to the CDN. CDN caches the photo and forwards it to the browser.
The issue with this photo storage infrastructure
For each photo uploaded, Facebook generates and stores four images of different sizes. Photos and the associated metadata lookups in NAS caused excessive disk operations of almost upto ten just for retrieving a single image.
The engineering team reduced the disk operations from ten to three by reducing the directory size of NFS volume from thousands of files per directory to hundreds.
Fetching a photo from the storage comprised of multiple steps:
- Filename is translated into an inode number. An inode is a unique identifier for a file. It stores the attributes (metadata) and the disk location of the file object. Just this step has multiple sub-steps.
- The inode is read from the disk.
- The file from the inode number is accessed.
If you need to understand inode, file handle and how network operations work in a distributed file system. This article on network file system discusses the concept in detail.
In the NAS system, reading the metadata from the disk was a bottleneck.
Most of the photo metadata went unread and consumed significant storage capacity. Also, the metadata was fetched from the disk into the main memory. For fetching photos at a scale of billions, this became a throughput bottleneck. This limited the number of reads that could be performed on a disk in a stipulated time.
What about using a CDN for serving photos?
Two issues with this:
Storing so much data on a CDN is not cost-effective.
CDN would only serve the recently uploaded and frequently accessed data. When it comes to user photos on a social network, there is a significant number of long-tail (less popular photos) requests. All the long-tail requests miss the CDN.
Haystack object storage
Haystack was designed with some key things in mind:
- High throughput and low latency. Keeping the disk operations for fetching a photo to at most one per read.
- Fault tolerance.
- Cost-effectiveness.
Keeping the disk operations for fetching a photo to at most one per read and reducing the photo metadata significantly enabling it to load in the main memory made Haystack a low latency and high throughput storage system.
Loading the metadata into the main memory significantly reduced the disk I/O operations providing 4x more reads per second than the NAS-based setup.
Haystack is made fault-tolerant and highly available by replicating photos across data centers in distinct geographical locations.
Learn to design distributed systems
If you wish to learn to design large-scale distributed systems starting right from zero, check out the Zero to Mastering Software Architecture learning track, comprising three courses that I’ve written.
The learning track educates you step by step on the fundamentals of software architecture, cloud infrastructure and distributed system design, starting right from zero. It takes you right from having no knowledge on the domain to making you a pro in designing web-scale distributed systems like YouTube, Netflix, ESPN and the like.
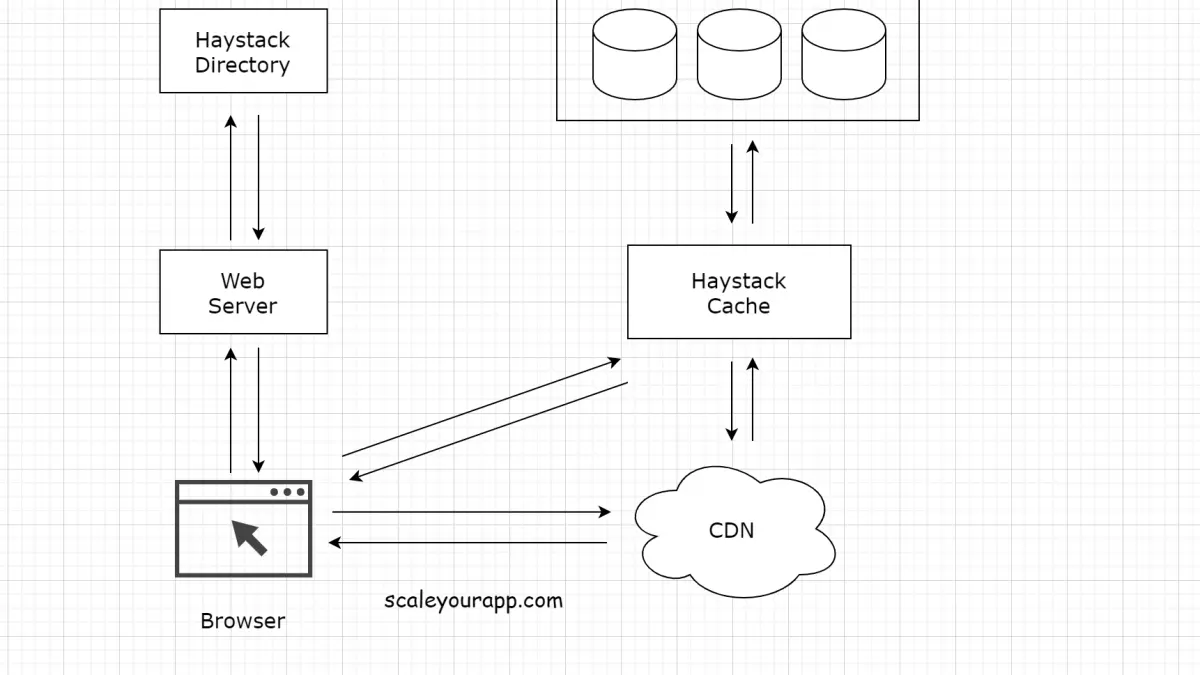
Haystack Architecture
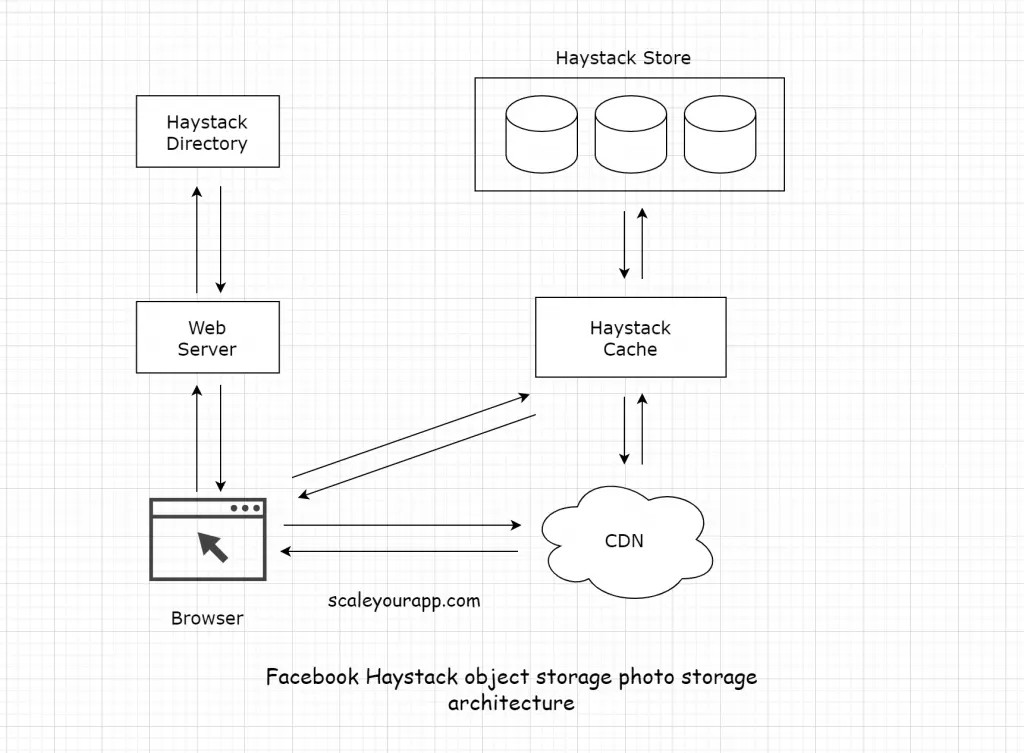
In this photo storage design, the popular images are served from the CDN and the long tail photos are handled by Haystack.
The Haystack architecture consists of 3 core components:
the Haystack Store, Directory and Cache.
When a user requests a photo, the browser requests the web server. The web server takes the help of the Haystack Directory to create the photo URL.
Haystack Directory
The Haystack Directory, besides creating the URL, maps logical volumes to physical volumes. The web server uses this mapping to create the photo URLs. This mapping also comes in handy when uploading photos.
The other functions of the directory are:
Load balancing writes across logical volumes and reads across physical volumes.
Determining if a request for a photo is to be handled by the Haystack cache or the CDN.
Identifying logical volumes that have become read-only either because of operational reasons or having reached their storage capacity.
The photo request is then routed to the CDN. If the CDN misses it, the request moves forward to the Haystack Cache.
Haystack Cache
The cache is a distributed hash table that uses photo id as a key to locate the data. If the cache doesn’t hold the photo, it fetches it from the store and returns it either to the CDN or the user’s browser.
The cache is primarily used to intercept the requests for the write-enabled Haystack store machines. Because as soon as a photo is uploaded, there is a read request for it. And the file systems of the photo storage workload perform better when doing either reads or writes but not both. The cache intercepts all the read requests for the write-enabled store machines improving the throughput. For this reason, the photos after upload on a write-enabled store are proactively pushed to the cache.
Haystack Store
The read-and-write requests to the Haystack Store machines are balanced by the Haystack Directory. The Store is the persistent storage system for the photos.
The read requests to the store hold information such as photo id for a certain logical volume and from a certain physical volume. If the store doesn’t find the photo, it returns an error.
To locate a photo, the store machine only needs the photo id and the logical volume id.
A store machine manages multiple physical volumes, each containing millions of photos. Each physical volume is of the size of 100s of GBs mapped to a logical volume.
The store’s storage capacity is organized by physical volumes. For instance, a 10 terabyte storage capacity server would consist of 100 physical volumes, each having 100 GBs of storage.
The physical volumes on different machines are further grouped into logical volumes. When a photo is stored on a logical volume, it is written to all the physical volumes corresponding to that logical volume.
This redundancy averts data loss in case of hard drive and other hardware failures.
Recovery from failures
The storage system runs on commodity hardware. The primary reasons for system failure include faulty hard drives, RAID controllers, motherboards, etc.
To ensure high availability of the system background tasks are run to detect and repair failures. Periodic checks are run to check the health of the store machines and the availability of the logical volumes.
If a problem is detected with any of the store machines, all the logical volumes on that machine are immediately marked as read-only.
The underlying failure causes are investigated manually.
Reference:
Finding a needle in Haystack: Facebook’s photo storage
Well, Folks! this is pretty much it. If you found the content helpful, consider sharing it with your network for better reach. I am Shivang, you can find me on LinkedIn here. Until next time. Cheers!



Follow Me On Social Media